達(dá)觀OCR首創(chuàng)無錨點(diǎn)文字提取算法,攻克行業(yè)難點(diǎn)
達(dá)觀OCR平臺基于自主研發(fā)的視覺技術(shù)�,結(jié)合知識增強(qiáng)的跨模態(tài)語義理解關(guān)鍵技術(shù)�,提供圖像矯正、圖像分割�����、版面標(biāo)簽分類�����、文字識別�����、信息扣取���、文檔比對�、表格識別、文字過濾��、信息審核�����、文字二次加工等一整套全流程OCR模型定制與應(yīng)用能力���。
達(dá)觀自研OCR支持包括中文��、英文����、繁體中文�����、日語����、韓語、德語����、法語����、西班牙語在內(nèi)的數(shù)十種語言識別�����。

文檔智能是文檔信息識別與處理最重要的環(huán)節(jié)����。達(dá)觀OCR基于百萬級文檔數(shù)據(jù)預(yù)訓(xùn)練跨模態(tài)理解模型,借鑒人類閱讀理解方式�����,綜合文本�、布局和圖像信息�、讓計(jì)算機(jī)像人一樣理解文檔版面布局、語義信息����。

達(dá)觀OCR采用機(jī)器學(xué)習(xí)來讀取和處理任何類型的文檔,可以精確地提取文本���、手寫字�、表格和其他數(shù)據(jù),無需人工干預(yù)����,快速自動處理文檔。無論是自動信貸審批單還是財(cái)務(wù)報(bào)銷發(fā)票�,都可在數(shù)秒內(nèi)完成關(guān)鍵信息提取,此外還可以添加人工審核���,對模型提供監(jiān)督����,并對敏感數(shù)據(jù)執(zhí)行審核���。
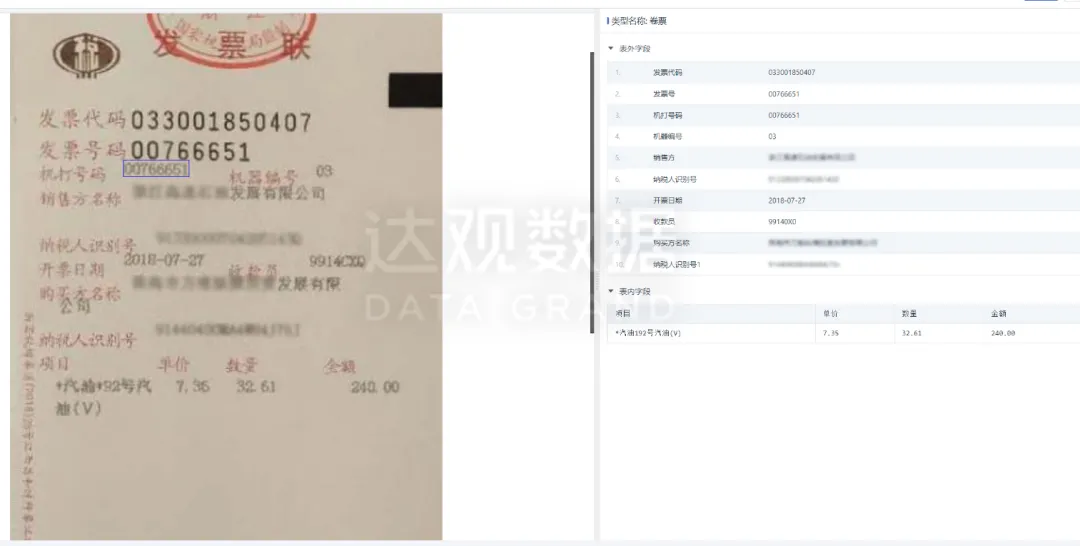
復(fù)雜表格識別一直是行業(yè)難點(diǎn)��。各種文檔表格樣式不一�����、排版極為復(fù)雜�。為此����,達(dá)觀OCR表格識別算法采用空間位置關(guān)系特征結(jié)合語義信息���,快速定位表格位置、還原表格結(jié)構(gòu)�、循環(huán)抽取重要信息、輸出結(jié)構(gòu)化表格數(shù)據(jù)�����。
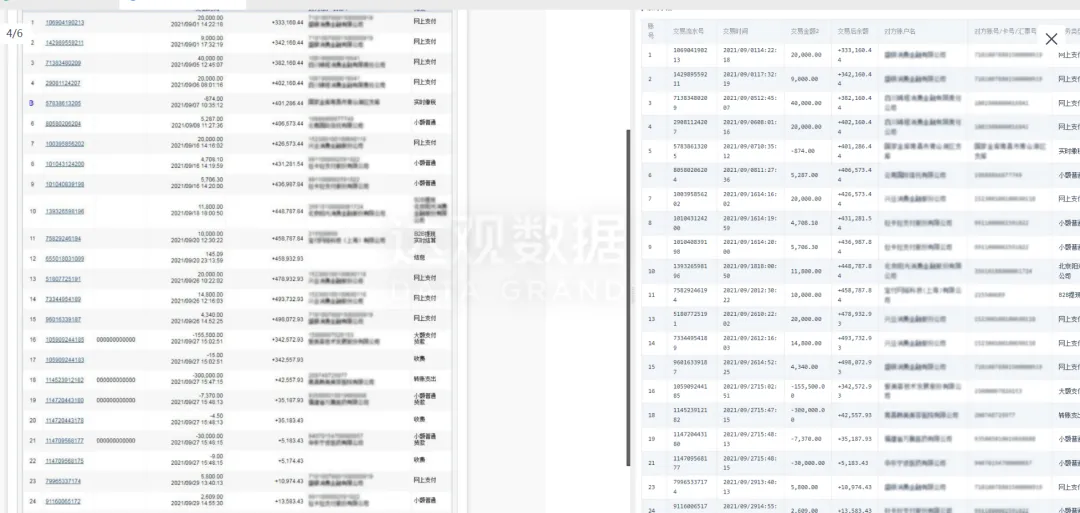
達(dá)觀自研OCR支持對圖片中的手寫中文��、手寫數(shù)字進(jìn)行檢測和識別���,針對不規(guī)則的手寫字體進(jìn)行專項(xiàng)優(yōu)化識別����,確保識別精度�����。

達(dá)觀OCR首創(chuàng)無錨點(diǎn)文字提取算法�,支持可視化拖拽建模�����,無需人工版式配置或代碼開發(fā),鼠標(biāo)拖拽即可訓(xùn)練模型�。模型可自動對圖像拍照扭曲透視、二次打印偏移等情形進(jìn)行矯正識別�����,自適應(yīng)多種變化樣式��,1個(gè)模型即可覆蓋��,無需考慮同種票據(jù)的多種變化���。
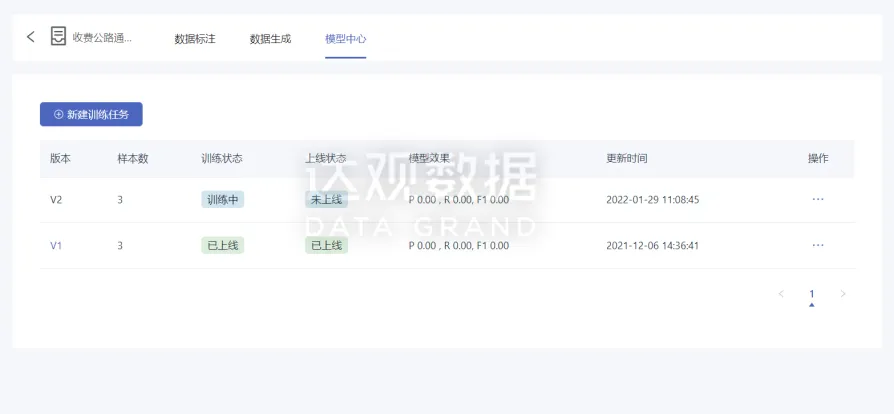
OCR將圖像文檔上的數(shù)據(jù)轉(zhuǎn)變成可由計(jì)算機(jī)識別理解的結(jié)構(gòu)化數(shù)據(jù)��,有效搭建知識橋梁�,構(gòu)建業(yè)務(wù)應(yīng)用�����。達(dá)觀OCR已服務(wù)于銀行�����、證券、保險(xiǎn)�、汽車制造、醫(yī)藥等眾多頭部客戶��,每年產(chǎn)生數(shù)以億級有效數(shù)據(jù)����,為客戶有效降本增效、防范風(fēng)險(xiǎn)��、創(chuàng)造多元業(yè)務(wù)價(jià)值�。






